Zscalerのブログ
Zscalerの最新ブログ情報を受信
購読するクラウドセキュリティSLAの理解を深めるためのガイド
SLAが重要な理由
このブログにおけるサービスレベル合意(SLA)は、スケーラブルで回復力があり、高いパフォーマンスを持つサービスを提供する能力に関する、クラウドセキュリティベンダーが掲げる指標を指しています。SaaSソリューションの人気が高まるにつれてSLAはより一般的となり、共有リソースの大規模なプールにおけるパフォーマンスや可用性などのサービスレベルを保証するようになりました。SLAは法的な面で焦点となることが多いものの、購入に携わるすべてのステークホルダーは、以下のような理由でベンダーのSLAを理解する必要があります。
- サービスに関連する信頼性、スピードおよび全体的なユーザエクスペリエンスがもたらすビジネスへの影響を把握すること。
- 契約にどのような除外項目が存在するかを理解することでリスクを定量化すること。
- 聞こえの良い言い回しを駆使して自社のSLAのクオリティを誇張するベンダーと、業界のリーダーとイノベーターとを区別すること。
この記事では、クラウドセキュリティベンダーやZscaler、ならびにその他に向けたSLAについて、以下のことを交えて説明します。
- 業界随一のSLAを提供する、Zscaler独自の要素について紹介すること。
- SLAの最も重要なコンポーネントを明らかにして分析し、プロキシの遅延に関するSLAを深掘りすること。
- 業界随一のSLAと、SLAが持つ本来の目的を損なう除外項目が多すぎるベンダーのSLAを区別するための評価基準を提示すること。
独自の要素を基にした、SLAへのZscalerのアプローチ
業界随一のSLAのカギは、業界最高レベルのセキュリティクラウドにあります。態勢が整っていないままSLAを確立することはできません。
Zscalerが提供する業界随一のSLAは、極めて重要なトラフィックを保護するために設計された、世界最大のセキュリティクラウドを10年以上にわたって開拓、構築、運用化してきた成果といえます。多くのベンダーが我々のアプローチを再現しようと試みてきましたが、技術面が不足しているため、一見すると優れているようでも実際の機能とは一致しないSLAが生み出されています。
このようなベンダーの主な性質は以下の通りです。
新しい市場への進出を試みている、ポイント製品のCASBベンダーの場合
- プラットフォームが、非常に重要なトラフィックをラインレートで処理する代わりに、REST APIを使用したSaaSアプリケーションの帯域外スキャンなどの単純なタスクを行えるよう設計されていること。前者を行うには、大きく異なるアプローチや構造が必要となります。
- 製品開発戦略が、各顧客固有の問題点を割り出して解決していくのではなく、大手のアナリストレポート(例:Gartner Magic Quadrant)に先駆けて必要とされる機能を発表することに重点を置いていること。
- 長年にわたりスケーラビリティを実現できていない、プロキシオープンソースであるSquid上に構築されたアーキテクチャを持つこと。
現代の環境でも通用するように努めている、従来型のハードウェアベンダーの場合
- IaaS(例:GCPやAWS)におけるシングルテナント仮想アプライアンスの転用を行っており、コンピューティングデータセンタが限られているほか、責任共有モデルが適用され、可用性の信頼性も低いこと。
- 既存および新規のサービスに追加していく仕組みにより、追加機能ごとに複雑さとレイテンシが発生すること。
- VMファイアウォール用のサービスとOSの更新が不定期であること(例:OS更新プログラムが物理ファイアウォールからパブリッククラウドでホストされているVMファイアウォールに移行するまでに6~9か月を要する)。
これらのアプローチは、質の高いサービスやそれに伴うSLAを提供する上で大きな制限があることが明らかになっています。詳細については、以下で詳しく説明します。
Zscalerが誇るプラットフォームの規模
ベンダーのSLAを評価するにあたって、本質的に評価の対象となるのは、ベンダーのクラウドプラットフォームの強度です。一般に公開されている、規模とパフォーマンスに関するデータがなければ、プラットフォームとそれに伴うSLAを本当の意味で評価することはできません。Zscalerは、規模とパフォーマンスに関する裏付けのためにデータを公開している、業界で唯一のベンダーです。
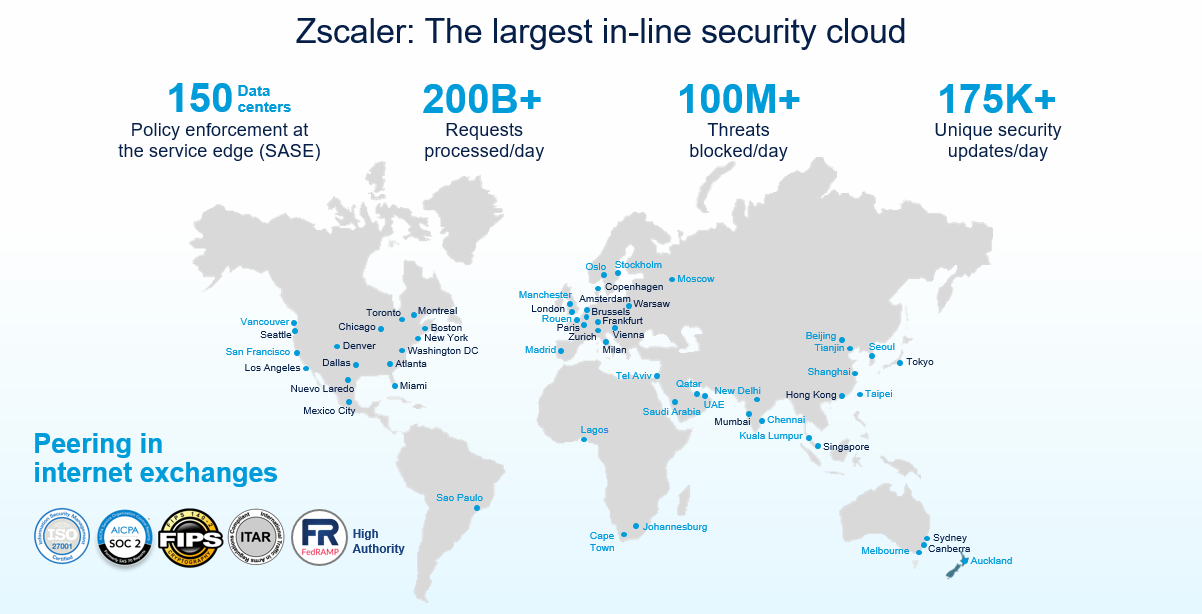
世界各地に展開されるZscalerのクラウド:100%コンピューティングデータセンタ(オンランプや仮想PoPなし)
当社は規模に関して大きな自負があり、常にリアルタイムのデータを公開しています。最新の指標はZscaler Cloud Activity Dashboardで確認できます。
考慮すべき点
サービスのスピードが優れているとうたうベンダーであっても、規模やクラウドの運営方法に関するデータや指標を一般公開していない理由は何でしょうか?
ZscalerのSLA : 高い可用性と優れたセキュリティ、そして卓越したスピード
これこそが製品情報シートに記載されている、Zscaler Internet Access (ZIA)のSLAの本質です。業界随一のセキュリティクラウドを運用するには、同じく業界随一のSLAが欠かせません。
1. お客様にとって利便性の高い、高可用性のSLA
一般的に、ベンダーは可用性について他社と競合しており、9をもとにした数値(99.999%など)を理想としています。9が多ければ多いほど、可用性についての取り組みが徹底されていることを意味します。たとえば、あるベンダーの可用性が99.9%である場合、サービスが停止する時間は1年間に525分未満となります。計算式は(1 - 99.9%) x 525,600(1年間は525,600分のため)となります。可用性が99.999%の場合、1年間のダウンタイムは6分以下に収まります。
ZscalerのSLAにおいては、サービスが利用できなかった時間の割合ではなく、ダウンタイムまたは速度低下の結果として失われたトランザクションの割合に基づく、革新的な合意が提供されています。お客様にとって利便性の高いこのSLAは、ダウンタイムがもたらした重要なビジネスへの影響と密接に関連しており、たとえサービスが100%利用可能であっても、予期しない混雑が発生したことでお客様へのサービスが遅くなった場合、クレジットが発行されます。
考慮すべき点
通信上の混雑が原因でトランザクションが20%減少した場合、ベンダーはサービスが100%利用可能であると言えるのでしょうか?
IaaSで従来型のシングルテナントVMを稼働するリフト&シフトのベンダーが、基盤となるインフラストラクチャの制御が得られず予測も不能であるために、最も苦労しているのはこの点です。こういったベンダーのSLAには多数の除外項目が載っていることが多く、結果的にSLAの目的を果たせなくなってしまうという事態は非常によく見られます。
以下の例では、従来型の次世代ファイアウォールベンダーが計画外のアップグレードをSLAから除外されているため、価値が失われています。

考慮すべき点
クラウドで予想外の機能停止が予告なしに発生した際でも、それがダウンタイムとしてみなされないことはあるのでしょうか?
別の例としては、同じ従来型の次世代ファイアウォールベンダーがSLAからスケールイベントを除外しています。

考慮すべき点
クラウド配信型サービスの主な目標は、スケーリングにおけるオーバーヘッドと不安材料を取り除くことではないでしょうか?
2. 100%既知のウイルスキャプチャSLA(優れたセキュリティ)
ハイパースケールプロキシは、非常に高速なユーザエクスペリエンスを提供するだけでなく、ショートカットなしで優れたセキュリティも提供できる必要があります。スキャンせずにポイントAからBにパケットを転送するだけでいいのであれば0msのレイテンシを実現できるかもしれませんが、セキュリティは壊滅的になるでしょう。既知のウイルスキャプチャSLAは、業界のみを対象とした業界初のシステムで、優れたセキュリティの実現に向けて結果を出すことを念頭に置いています。Zscalerは、既知の全マルウェア/ウイルスが当社のプラットフォームを介して漏洩するのを100%防止すべく努めています。これが実現できなかった場合、その都度クレジットを発行します。
他のベンダーの中には、アーキテクチャやスケーラビリティ、または回復性における制限のためにスキャンを行えず、CDNやファイル共有サービスなどの「安全であるとされている」経路でトラフィックを通過させている、SLAの取り扱いが徹底されていないものもあります。このような考え方は、信頼されている評判の高いソースを介して展開される脅威の数が増加の一途をたどり、脅威をとりまく情勢が変化を続けるなかでますます時代遅れとなっています。
考慮すべき点
CDNやパブリッククラウドプロバイダ、ファイル共有サービスからのすべてのトラフィックを信頼できるとみなせるのでしょうか?
3. 低プロキシレイテンシSLA(驚異的なスピード)
暗号化されたトラフィックを制限なしで検査し、脅威とデータ損失に対する防止エンジンを同時に適用すると、CPUサイクルがかなり消費されますが、これは当然のことです。そのためZscalerでは、優れたユーザエクスペリエンスを備えた非常に効果的で効率的なセキュリティとデータ保護に注力しています。
プロキシレイテンシSLAの深堀り
ユーザエクスペリエンスを最適化する際、ネットワークとプロキシのレイテンシ両方を考慮する必要があります。ネットワークレイテンシの最適化については別の投稿で取り上げますが、簡単に言うと、ネットワークレイテンシとはクライアントとZscaler間にかかる時間にZscalerとサーバ間にかかる時間を加えたものです。ネットワークとプロキシレイテンシの両方が、広範なサービスエッジのプレゼンスとエクスチェンジピアリングの機能によって大幅に最適化されているのですが、ここで中心となるのはプロキシレイテンシです。

プロキシレイテンシは、HTTP/Sリクエストのスキャンのためにプロキシによって生じた追加時間(ミリ秒単位)に、HTTP/S応答のスキャンのための追加時間を加えたものに関するレイヤ7の指標です。上の図では、プロキシレイテンシはXms(リクエスト)+Yms(応答)になります。レイヤ7のプロキシとして、Zscalerはリクエストヘッダー/ペイロードとレスポンス ヘッダー/ペイロードの両方で多くのセキュリティおよびデータ保護エンジンを実行するため、これらの双方を捉えることが重要です。
このプロキシレイテンシを排除することは、残念ながら不可能です。すべてのトランザクションをスキャンするにはCPUサイクルが必要ですし、これはごく自然なことです。ただし、このプロキシレイテンシの最適化は可能です。これについては、後ほど簡単に説明します。
業界随一のプロキシレイテンシSLAを提供する最適な方法
残念なことに、べンダーの中には、SLAの除外項目を事細かく記載し、SLAの本来の目的が損なわれてしまっているものもあります。したがって、ベンダーが何を除外しているのか、レイテンシをどのように計算しているか、そしてSLAがあまりにも良好な数値となっていないかどうかを確認するようにするのが重要です。
1. 脅威とDLPのスキャンを含めること
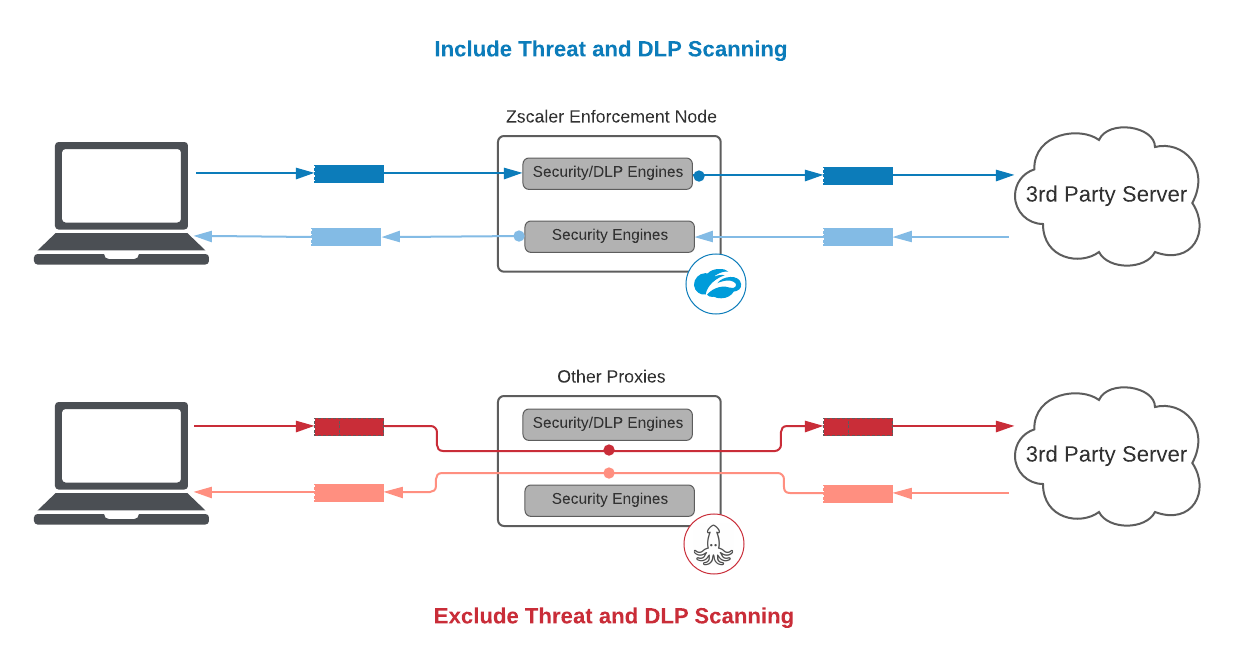
セキュリティサービスとして、脅威ならびにDLPのスキャンを除外することはSLAの本来の目的に反します。
特段の作業を行わず、一方から他方にパケットを転送すること自体はそう困難ではありません。ベンダーが提示しているレイテンシの数値が信じがたいほど良好である場合、注意が必要です。実際、もしZscalerが脅威やDLPのスキャンが含まれないSLAを提供する場合、復号化されたHTTPSトランザクションとプレーンテキストHTTPトランザクションの95パーセンタイルに対してそれぞれ25msと5msの契約を提供することができます。これは一般的なベンダーの2倍もの数値ですが、当社としてはこれは本来のパフォーマンスを反映した数値ではなく、お客様にとって大きな誤解を招くものであると考えます。
例えば、インライントラフィック処理用に構築されていないポイント製品のCASBベンダーの本当の性質は、注意事項の部分に現れます。

プロキシレイテンシSLAは、各種エンジンによってもたらされた追加時間を排除すべきではありません。
2. 透明性を確保すること
すべては論より証拠です。クラウドセキュリティプロバイダが掲げるレイテンシの数値に関しては、常に疑ってかかる必要はありませんが、検証は行うようにしましょう。
プロキシレイテンシSLAは、ベンダーが提供するレポートとトランザクションレベルの指標で補完し、SLAに対する責任はベンダーが負う必要があります。データがなければSLAは無意味であるといえます。
トランザクションレベルの詳細は、レイテンシがもたらす影響を本当の意味で証明するもので、透明性とトラブルシューティングにおいて不可欠です。不適切なアーキテクチャの選択と過剰なSLAの設定が相まって、一部のベンダーはこの要件を満たすのが困難な状態に陥っています。
- 新しい市場への拡大進出を余儀なくされている、ポイント製品CASBベンダーの場合:スケーラブルでないオープンソースのプロキシプロジェクトに依存した場合、トランザクションレベルのログを捉えることができるエンタープライズグレードのロギングプレーンは利用できません。これは、本投稿を読んでいるSOCの関係者の方には特に注意していただきたい点です。このアプローチでは、SLAをトランザクションレベルで報告することはできません。
- 現代の環境でも通用するよう努めている、従来型のハードウェアベンダーの場合:IaaS上のファイアウォールVMでさまざまな機能を追加していくと、レイテンシの数値が細分化され、エンドツーエンドのプロキシレイテンシをリアルタイムで報告できなくなります。
既知のCASBベンダーは透明性を提供できない、または提供を躊躇しているために、1時間平均のレイテンシに関する問題を隠すための様々な手法を取らざるを得ないのが現状です。トランザクションレベルでログを行えないため、平均値は変動性の高い時間帯に人為的に歪められて記録されます。
Zscalerのソリューションは透明性を念頭に置いて構築されています。当社は、お客様が知る必要のある可視性を提供することができ、以下のようにして実際に提供しています。
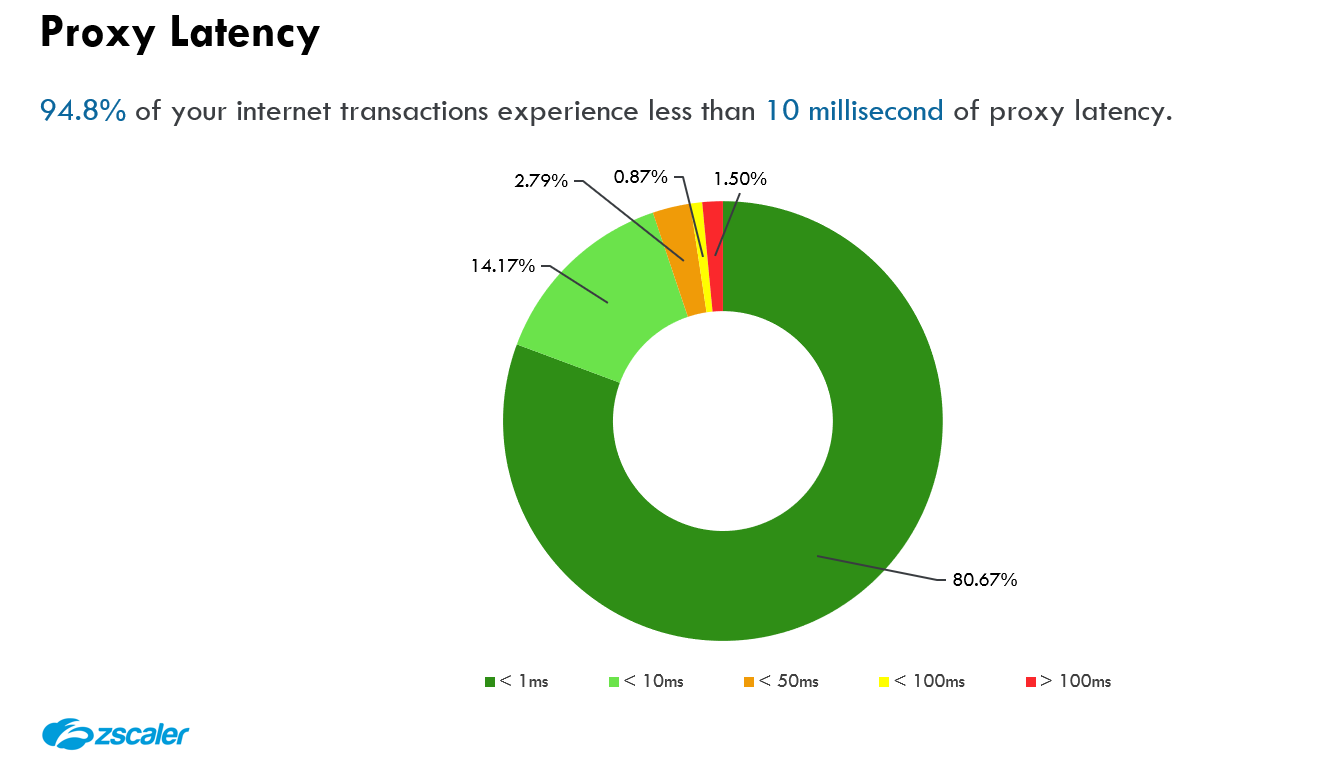
Zscalerが提供する四半期のビジネスレビュー(QBR)におけるレイテンシレポート

トランザクションレベルのプロキシレイテンシの可視性を表示する、ZscalerのWebインサイトログビューア
3. プロキシトランザクションのレイテンシとファイアウォールのパケットレイテンシの比較に集中すること
パケットレイテンシは、特にWeb中心の環境において、レイテンシの全体像を示すには不完全です。
ここではプロキシレイテンシについて取り上げているので、比較的簡潔な説明に留めますが、根本的な違いを理解することは重要です。パケットレイテンシは、物理または仮想ファイアウォールアプライアンスがリクエストパケットを処理するのにかかる時間(入力から出力までの時間)の尺度ですが、この指標には欠陥があります。リクエストの処理時間の測定は、トランザクション全体のレイテンシのわずか一部にすぎず、情報を受け取り直すことに関する、レイテンシの重要な側面が見落とされています。その性質として、ほとんどのWebトラフィックはペイロードは小さいものの応答が大きいGETであり、これをWeb中心の環境でレイテンシを測定する方法と捉えるのは大きな間違いです。
最高水準のプロキシレイテンシを実現するZscaler独自の要素
クラウドのインフラストラクチャのスケールアップとスケールアウトが最初のステップですが、最適なソリューションには適切な基盤となるアーキテクチャが必須です。Zscalerはシングルスキャンマルチアクション(SSMA)と呼ばれる並列のセキュリティサービスを使用して、すべてのパケットを非常に効率的にスキャンします。
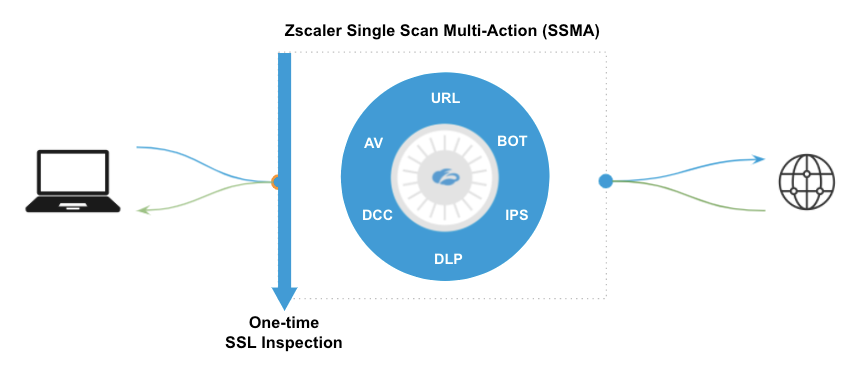
Zscalerのシングルスキャンマルチアクションエンジンが並行して作動
SSMAは、セキュリティ関係者が数十年にもわたって実装を切望してきたものの体現ともいえる、最高水準のセキュリティと高速なユーザエクスペリエンスを両立させる単一のプラットフォームです。SASEフレームワークにおいて、Gartnerはこれを「回線速度での暗号化されたトラフィックとコンテンツのシングルパス検査」と呼んでいます。
従来型のアーキテクチャでは、サービスチェーンアプライアンスやクラウドベースのサービス、またはその両方の組み合わせのいずれであっても、パケットは1つのVMから別のデータセンタ、または完全に異なるクラウド内の別のVMにメモリを残す必要があります。ネットワーキングなどに関する特別な知識がない場合でも、それがいかに非効率的で複雑であるか想像できるでしょう。
Zscalerは、最適化されたデータパス用に設計された、高度に最適化されている専用のサーバ内の共有メモリにパケットを配置する、クラウドネイティブのアーキテクチャで構築されました。さらに重要なのは、Zscalerノード上のすべてのCPUがこれらのパケットに同時にアクセスできる点です。各機能に専用のCPUを持たせることで、すべてのエンジンが同じパケットを同時に検査することが可能です(シングルスキャンマルチアクションという名前もここに由来します)。これにより、サービスチェーンによる追加のレイテンシが発生しなくなり、Zscalerノードはポリシーに関する決定を非常に迅速に実施して、パケットをインターネットに転送することができるようになります。
要約すると、従来型の仮想アプライアンスを転用したり、追加されたエンジンでオープンソースのプロキシプロジェクトをホワイトラベルしたりしても効果はありません。このようなアプローチには、対処し切れないほどの従来型の技術負債が存在するのです。
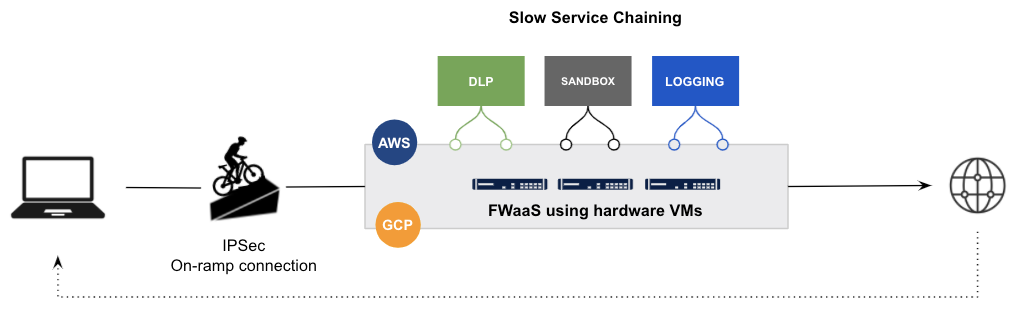
サービスチェーンを使用してIaaS上の従来型FW VMを転用する、従来型のベンダーの例
SLAに関してベンダーから正確な情報を得るには
この情報を有効活用するためのアドバイスとしては、サービスの利用を開始した多くのお客様ならびに利用を検討中のお客様は、ベンダーとSLAに関して話す際に可用性に対して特に注意を払います。確かにこれは非常に重要な要素ですが、ベンダーのサービス内容についての分析においてはまだ不完全です。
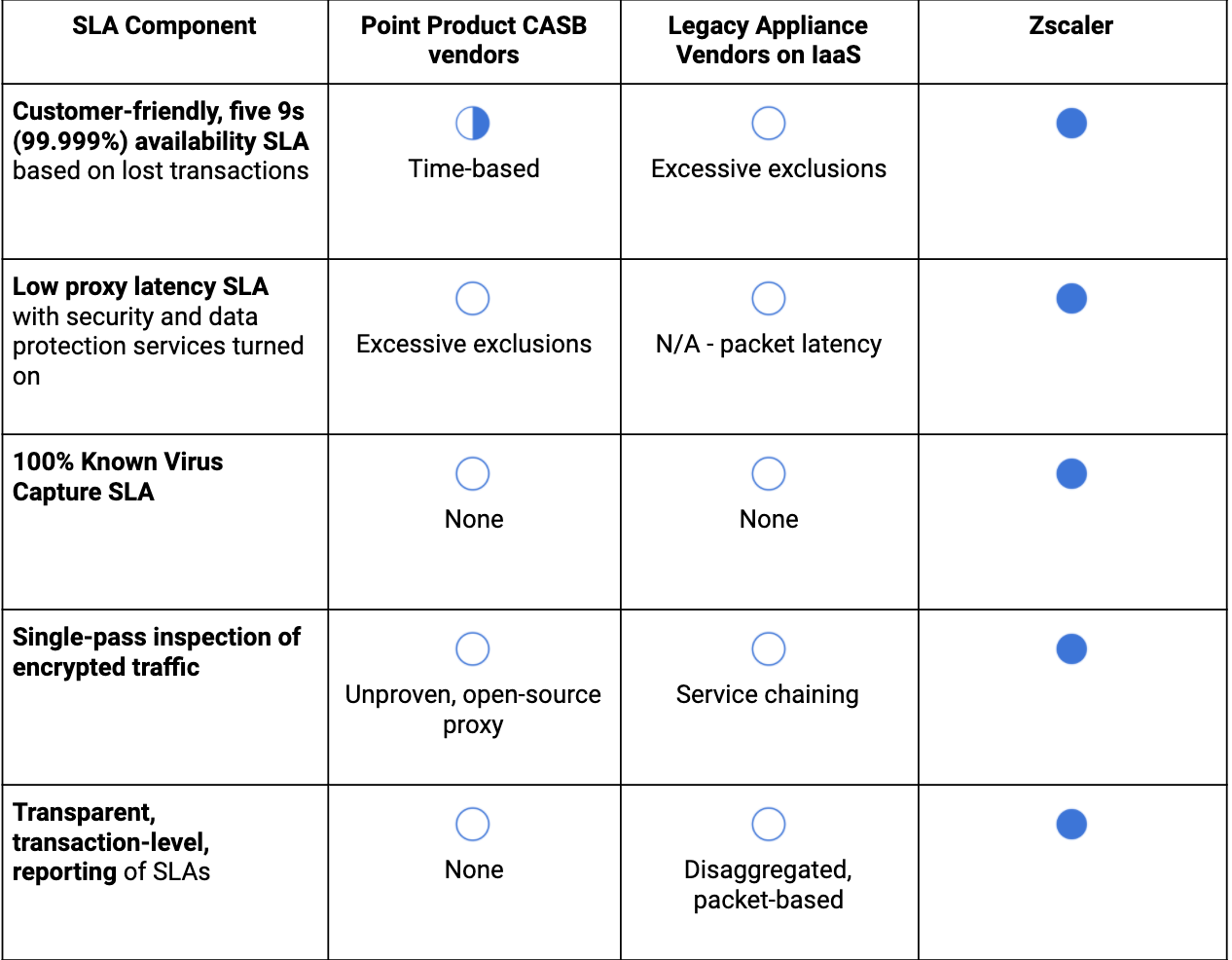
以下は、SLAの主要なコンポーネントを識別するために使用できる簡単な表です。